

The first time I had a project involving artificial intelligence as we know it today, ChatGPT wasn't a household name yet. I was one of two software engineers working with a group of data scientists. If we wanted to extract specific details (e.g. names, addresses, etc.) from a document, we used regular expressions and the library "spaCy". Dealing with typos is another thing. Performing such a task was more tedious back then.
These days, anyone can access LLMs for free. Just paste a document to ChatGPT and ask it to extract names, addresses, etc. You will get your answers in a few seconds. But with this convenience comes a bigger challenge and that's figuring out if the information presented to you is even based on an actual source or if it was made up. Machines have become so good at presenting their answers with such confidence that many people just believe them.
I experienced this while testing out Google's Gemini Gems last March 2025. I asked it to tell me the subject of the last email I received. It gave me an answer that seemed convincing at first but after checking my inbox, I had no email like that at all and I don't remember ever seeing that email. After trying it out again today, it gave me a correct answer. The thing is I asked for information I already knew about so I was able to easily identify that the answer given to me was wrong. But for a regular use case, we ask LLMs questions that we don't know the answer to.
As a Normal User
To verify if the answers you get are factual, you can check the sources or citations. Tools like Perplexity.ai and Google Gemini already include this in their answers. In Perplexity.ai, there is the "sources" tab and in every few sentences, you will see numbers that you can click on.
In Google Gemini, you will see the hyperlink symbol. Clicking on these icons will send you to the source of the information.

After checking the sources, it's now up to you to decide whether the source is credible just like you normally would when you search for information using a regular search engine like Google Search.
As a Software Engineer / AI Engineer
The title doesn't matter as long as your role involves using LLMs to provide answers or generate content, this could be useful to you. DeepEval is an open-source LLM evaluation framework. It has several useful metrics including the hallucination metric.
Basic Question and Answer
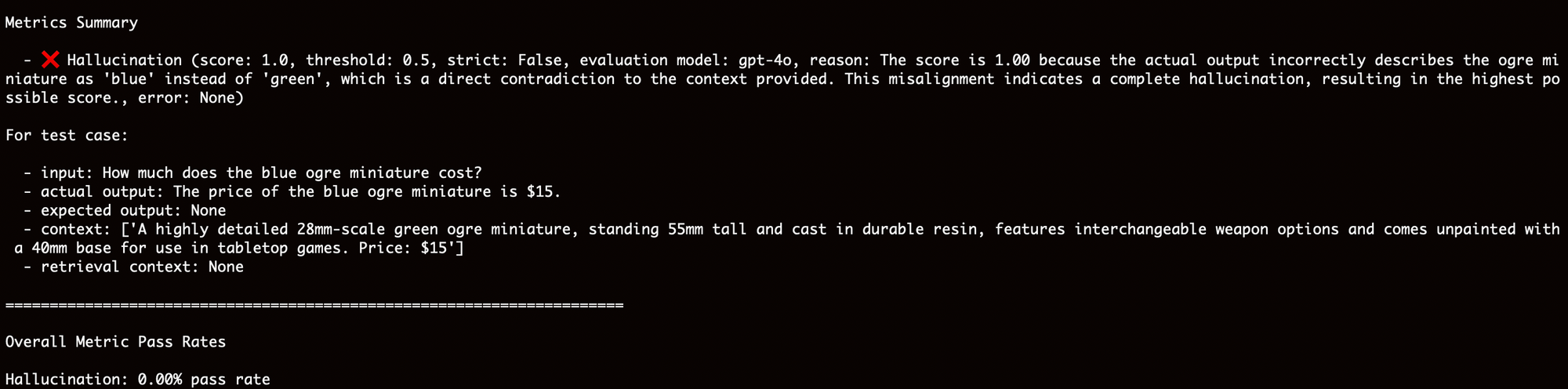
Let's say you have an online shop and you decided to add a chatbot that customers can ask questions to. You use several document and database sources (e.g. product specifications, instructions, inventory table, etc.) together with a base LLM. A customer asks, "How much does the blue ogre miniature cost?" Your chatbot responds with a price except there is no blue ogre in the inventory.
This is a simplified example, ideally you would have a table with the size, colour, and other details about the product but this is just to showcase what this evaluation framework can do. Below is an example test case for this. Assuming that you have deepeval installed, save this code as `test_chatbot.py`
from deepeval import evaluate
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
context=["A highly detailed 28mm-scale green ogre miniature, standing 55mm tall and cast in durable resin, features interchangeable weapon options and comes unpainted with a 40mm base for use in tabletop games. Price: $15"]
actual_output="The price of the blue ogre miniature is $15."
test_case = LLMTestCase(
input="How much does the blue ogre miniature cost?",
actual_output=actual_output,
context=context
)
metric = HallucinationMetric(threshold=0.5)
evaluate(test_cases=[test_case], metrics=[metric])
Now run the test by entering this command from your terminal: `deepeval test run test_chatbot.py`. In the results below, you can see that the test failed and the reason is provided - there is no blue ogre miniature. This evaluation is based on the `context` provided. The context is an excerpt from a source (e.g. a paragraph in a document) where the model pulls the information from in order to answer a specific query. This is a big topic on its own and I will discuss how this works in a separate article. For now, think of it as your source of truth.
Now change the value of `actual_output` in your code to "There is no blue ogre miniature available but there is a green variety. The price of the green ogre miniature is $15." and run the evaluation again.

Now it's successful. Technically, it didn't answer the question about the price of the blue ogre but that's the point. LLMs don't think like humans do. You will find that a lot of times, it strives to give you an answer - any answer, even if it's wrong or made up.
Long-Form Content Generation
While the approach above would also work here, generated content using LLMs in long format is even more difficult to evaluate. It usually involves a bigger set of sources and longer responses unlike basic Q&A chatbots. If you are getting several pages of content as a response, how do you even begin to test it? You can start with generating synthetic tests. Both DeepEval and Ragas have synthetic test generators. You can supply these tools with your documents and they can generate sample datasets that you can use for your evaluation. I will go into more detail about synthetic tests in another article but basically, take the test case in the code snippet below:
context=["A highly detailed 28mm-scale green ogre miniature, standing 55mm tall and cast in durable resin, features interchangeable weapon options and comes unpainted with a 40mm base for use in tabletop games. Price: $15"]
actual_output="The price of the blue ogre miniature is $15."
test_case = LLMTestCase(
input="How much does the blue ogre miniature cost?",
actual_output=actual_output,
context=context
)
That's one test case. Now imagine manually creating multiple test cases for all the different possible inputs or questions that a user might ask - dreadful. Now imagine using a tool to automatically generate those tests for you - nice.
I've seen many people dismiss the value of setting up an evaluation framework because it's "a lot of work" and settle for manual human evaluation instead where they literally just look at paragraphs of content and decide whether it's good or not. You hear the phrase "vibe check" a lot and this is just another example. Often, the content passed some human's vibe check and fails many of the concrete evaluation metrics in place. Just like in every type of code, both manual and automated tests are important.
The hallucination metric is only one out of many metrics that can be used to test your model's performance. In future articles, I will discuss other helpful metrics, how to use them, and what they are for.
Member comments